|
|
Ähnliche Berichte:
|
Papers in anderen sprachen:
|
|
|
informatik referate |
Datenkompremierung (File Compression):
Dieser Algorithmus behandelt in erster Linie die Platzreduzierung und erst in zweiter Linie behandelt er die
Zeitreduzierung. Diese Technik heißt auch Kodierungsmethode.
Im allgemeinen haben Dateien einen hohen Grad an Redundanz. Die Verfahren die wir untersuchen sparen
Platz weil die meisten Dateien einen relativ geringen Informationsgehalt haben
Einsparungen kann man bei einer Textdatei von % bis % haben, jedoch bei einer binären
Datei hat man Einsparungen von % bis %. Doch es gibt auch Datentypen bei dem man nur wenig einsparen kann, solche die aus zufälligen Bits bestehen.
Tatsächlich ist es so, daß Mehrzweck-Verfahren gewisse Dateien verlängern müssen, den sonst könnte man das Verfahren wiederholen und dadurch beliebig kleine Dateien erzeugen.
) Laufl ngenkodierung Run-Length Encoding):
Man spricht hier von einen Lauf (run) dann, wenn sich lange Folgen sich wiederholender
Zeichen darstellt.
Siehe dieses Bsp sprich 1.Metode
AAAABBBAABBBBBCCCCCCCCDABAAABBBBCCCD
Diese Zeilenfolge kann viel Kompakter kodiert werde, indem man die wiederholenden Zeichen nur einmal angibt und die Anzahl der Wiederholungen davor schreibt.
Also würde dann unser Bsp. kodiert so aussehen:
4A3B2A5B8CDABCB3A4B3CD
|
Bei einem Bitraster würde die Lauflängenkodierung so aussehen: Methode oder Bsp.: | ||||
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
3 |
|
|
|
| ||
|
|
|
| ||
|
|
|
| ||
|
|
|
| ||
|
|
|
| ||
1 2 46 2
Hier in diesem Bitraster sieht man rechts eine Liste von Zahlen, die einen Buchstaben in einer kompremierten Form speichern können.
Man gibt nun links davon die jeweiligen Häufigkeiten an wie oft nun diese Null oder Eins vorkommt, zB.: in der ersten Zeile, sie besteht aus 8 Nullen 4 Einsen und dann folgen wieder
Nullen usw geht es mit den anderen Zeilen.
Man sieht also, daß es wesentlich besser ist die kodierte Form zu übergeben als die unkodierte, und man kann auch so wieder den Bitraster rekonstruieren.
Man hat dadurch eine recht große Einsparung, denn man 5 Bits bei unkodierten Darstellung verwenden, aber jedoch nur 4 Bits bei der kodierten Darstellung, ergibt eine Einsparung von 1 Bits.
) Kodierung mit variabler L nge Variable Length Encoding):
Dieses Datenkompressionsverfahren spart beträchtlich Platz bei Textdateien.
Nehmen wir an wir wollen eine Zeichenfolge "ABRACADABRA" kodieren, und dieses mit dem herkömmlichen Verfahren des binären-Codes, bei einer Binärdarstellung mit Hilfe von 5 Bits zu Darstellung eines Buchstabens. Dann lautet die Bitfolge so:
Um diese zu dekodieren, nimmt man sich 5 Bits her und wandelt sich nach dem Binärcode um.
Nun ist dieses ziemlich unpraktisch, denn der Buchstabe D kommt nur einmal vor, aber der Buchstabe A
jedoch 5 mal und ich muß A jedesmal die selbe Bitfolge aufschreiben und wieder dekodieren.
Es wäre doch besser wenn man versuchen würde, häufig verwendete Buchstaben eine kürzere Bitfolge zuzuweisen, indem man sagt A wird mit 0 kodiert, B mit , R mit , C mit 0 und D
mit 11, so daß dann aus ABRACADABRA dann diese
1 0 0 0 1 0 1 1 0
Bitfoge dann werden würde. Diese ist schon wesentlich kürzer denn diese Bitfolge hat nur mehr
15 Bits benutzt als die vorhergehende die 5 Bits verbraucht hat. Doch hat dieser Code einen Haken, denn es ist kein wirklicher Code, da er abhängig ist von den Leerzeichen, ohne diese Leerzeichen würde nämlich
0 als RRRARBRRA heraus kommen.
Also muß man die Zahl mit Begrenzern dekodieren, aber dann noch ist die Zahl von 5 Bits plus
10 Begrenzern noch immer Kleiner als der Standart-Code.
Wenn kein Zeichencode mit dem Anfang eines anderen übereinstimmt werden keine Begrenzer benötigt. Deswegen werden wir die zu kodierenden Buchstaben anders gewählt, nämlich:
A mit , B mit , C mit D mit 0 und R mit
so gäbe es nur eine Möglichkeit die 5 Bits Zeichenfolge
zu dekodieren.
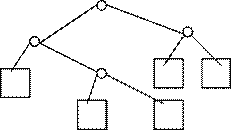
Eine noch einfachere Methode zur Darstellung eines Codes ist ein Trie.
Dazu ein Bsp.: Wir wollen wieder ABRACADABRA kodieren, aber dieses mal mit dem Trie.
Dazu sollte man wissen, daß man bei einem Trie immer von der "Wurzel" ausgeht und so sein Zeichen bestimmt. Wenn man bei einem Knoten angelangt ist, muß man sich entscheiden ob nach links oder rechts.
Für links muß man mit 0 codieren und für rechts mit
1.Bsp 2.Bsp:
A
R B D A
B C R
D
C
Nun, man sieht hier, daß der rechte Code um 2 Bits kürzer ist als der andere.
Die Trie-Darstellung garantiert also, daß kein Code für ein Zeichen mit den Anfang eines anderen Zeichen übereinstimmt, so daß sich die Decodierung für die Zeichenfolge eindeutig
festlegen lä t.
Doch welchen Trie soll man Benutzen? Hier gibt es eine Lösung bei der man bei gegebener Zeichenfolge einen Trie berechnen kann und der eine minimale Bitfolge hat.
Dieses Verfahren wird Huffman Kodierung genannt.
Erzeugung des Huffman-Codes Building the Huffman Code):
Bei dem Erzeugen des Huffman-Codes kommt es in erster Linie darauf an wieviel Zeichen
zu decodieren sind plus Leerzeichen. Nun ermittelt das folgende Programm die unterschiedlichen
Häufigkeit der Buchstaben eines Zeichenfeldes, und trägt sie dann in ein Feld count ] ein.
Nun wieder ein Beispiel das wir kodieren möchten, die Zeichenfolge lautet: A SIMPLE STRING TO BE ENCODED USING A MINIMAL NUMBERS OF BITS .
Der erste schritt ist der Aufbau eines Tries entsprechend seiner Häufigkeiten, dazu sollte man sich eine Buchstabentabelle machen.
A B C D E F G H I J K L M N O P
Q R S T U V W
X Y Z
k 0 1 2 3 4 5 6 7 8 9 10 1
2 3 4 5 6 7
8 9
0 1
2 3
4 5
26 count[k] 11
3 3 1 2 5 1 2 0 6 0 0 2 4 5 3 1 0 2 4 3 2 0 0 0 0 0

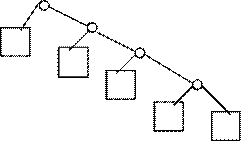
Danach kann man schon mit dem Trie beginnen, man fängt an in dem man die Buchstaben Knoten) mit der Häufigkeit 0 weglä t, und alle anderen Knoten mit ihrer Häufigkeit in einer Ebene darstellt. Nun nimmt man die Knoten mit den niedrigsten Häufigkeiten und fasse sie zusammen. Man nimmt nun die nächst höhere Häufigkeit und fasse sie wieder zusammen, dieses geht so lange weiter bis alle Häufigkeiten in
einem Baum dargestellt sind.
Beachten muß man jedoch daß die sich Knoten mit geringer Häufigkeit weit unten im Baum befinden und
Knoten mit hoher Häufigkeit weit oben im Baum befinden.
Die Quadratischen Knoten sind Häufigkeitszähler und die runden Knoten sind Summen Knoten und lassen sich durch ihre Nachfolger wieder darstellen.
Implementation (Implementation :
Bei der Implementation kommt es mehr darauf an den Huffman-Code richtig anzuwenden bzw. die Vorausberechnen richtig zu rechnen um denn daraus eine effiziente Kodierung zu kriegen. Man sollte hier einen Trie finden der die Häufigkeit der Buchstaben berechnet oder für Zeichen
verwendet, deren Häufigkeit in einem Pascal Programm auftritt zB.: ; und dafür eine Bitfolge reserviert.
So ein Kodierungsalgorithmus kann mit Hilfe des Huffman Codes % Einsparung liefern.
| Referate über:
|
|
Datenschutz |
| Copyright ©
2025 - Alle Rechte vorbehalten AZreferate.com |
Verwenden sie diese referate ihre eigene arbeit zu schaffen. Kopieren oder herunterladen nicht einfach diese # Hauptseite # Kontact / Impressum |